Analysis of Ethan Winer's Bit-Depth Listening Test
Notes by ff123
Introduction
Ethan Winer prepared a listening test of five wav files of
different bit-depths, writing:
Your challenge is to download the five Wave files linked
below, and see if you can identify which file has what resolution. But you have to tell
which is which by listening to them. No fair looking at the bits in an editor program!
Each of the Wave files below are just over 2.2 MB in size. Again, one file was dithered
from 24 bits to 16, another was truncated, and three others were reduced to
(approximately) 13 bits, 11 bits, and 9 bits respectively.
Ethan advertised for listeners on various audio forums and on Usenet
in rec.audio.pro. Enough people participated to be able to perform an analysis, which is
presented here. The results of interest are:
1. For the group of people who participated (21
useful responses), the 9-bit and 11-bit files were the only ones audibly different from
the 16-bit files. The 13-bit file was not audibly different from the two 16-bit files, nor
were the two 16-bit files audibly different from each other.
2. In contrast to the group results, two listeners
demonstrated that they could distinguish between the two 16-bit files, both indicating a
preference for the truncated 16-bit file.
Other Related links
Critique of File Preparation
I looked at the files within Cool Edit to make sure
that the bit-depths were as claimed and that they were reasonably well-aligned in time. I
noted the time offsets shown in the table below, where File 3 starts the earliest. So for
example, File 3 has already been playing 10.1 milliseconds before File 4 starts. To
prepare the files for bit-depth analysis, I then trimmed the start of every file (except
File 4) so that they had perfectly synchronized starting points. Then I trimmed the end of
the files so that they were exactly the same length.
| File |
Bit-depth |
Samples |
Offset
(milliseconds) |
| 1 |
16 bits, dithered from 24 |
319 |
7.2 |
| 2 |
16 bits, truncated from 24 |
127 |
2.9 |
| 3 |
13 bits |
0 |
0.0 |
| 4 |
11 bits |
447 |
10.1 |
| 5 |
9 bits |
383 |
8.7 |
To compare the relative bit-depths of two files, I
inverted and mix-pasted one into another file. The images below show the results of these
operations. I have chosen to show only the right channel for simplicity. Notice that the
last second of the files are not even close to the expected sample level difference. I'd
guess this is where Ethan applied a fade-out of the music, but perhaps he applied it after
he changed the bit-depths (?). Also, something is obviously wrong with the 11-bit file,
because the differences between 11-bits and truncated 16-bits are not random as are the
other differences, but instead are correlated with the music.
In general, the expected peak-to-peak sample level
difference between two files of different bit depths is 2^(b1 - b2), where b1 and b2 are
different bit depths. So to calculate the effective bit-depths, I determined the
peak-to-peak sample levels of the difference signal, then worked backwards. To determine
the peak-to-peak sample level difference between the truncated 16-bit file and the 11-bit
file, I first highpass filtered the difference signal at 15 kHz to remove most of the
correlated signal. This isn't a perfect procedure, but it should be in the ballpark.
Conclusion: File preparation is
flawed. The fadeout should have been handled better. The error in the 11-bit file should
have been noticed and corrected, and although 10 milliseconds of time offset is probably
not enough to influence listening results, the files could have been aligned exactly.
| Files |
Actual
Sample level
peak difference |
Effective
Bit-depth |
Invert/Mix-paste
Result
Waveform view
(click to enlarge) |
Invert/Mix-paste
Result
Spectral view
(click to enlarge) |
13-bit vs.
truncated 16-bit |
+ 5 |
12.7 |
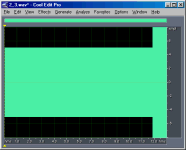 |
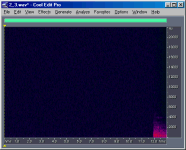 |
11-bit vs.
truncated 16-bit |
+ 18 (*) |
10.8 (*) |
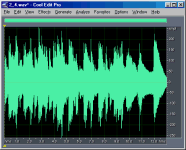 |
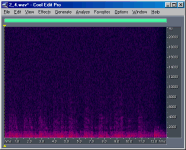 |
9-bit vs.
truncated 16-bit |
+ 50 |
9.4 |
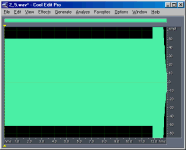 |
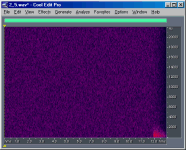 |
(*) Effective bit depth determined by first
high-pass filtering the difference signal above 15 kHz to remove most of the correlated
signal.
The following images show the difference signal in
waveform and spectral view for the 16-bit files. I don't know what the exact dither
algorithm used was (Ethan notes that it is SAWPro's "Dither Type 2" algorithm),
but the spectral view (if one increases the contrast) shows that there is less energy at
lower frequencies than at higher frequencies, which says that some dither noise-shaping
has been applied. The point of dither noise shaping is to push some of the noise out of
the sensitive frequency region of hearing at the expense of increasing noise in less
sensitive regions. Again, note that the sample level of the last second is much larger
than it should be for this difference signal.
| Files |
Actual
Sample level
peak difference |
Invert/Mix-paste
Result
Waveform view
(click to enlarge) |
Invert/Mix-paste
Result
Spectral view,
contrast increased
(click to enlarge) |
Dithered 16-bit vs.
truncated 16-bit |
+ 2 |
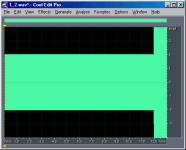 |
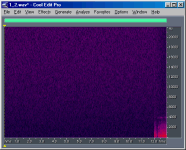 |
Critique of Test Method
There are several things about the test method which
could have been improved:
1. Instead of being asked to correctly identify each
file, the listeners should have been provided a reference file, and asked to rate the
sound quality of each file against the reference. The ideal reference file would have been
the 24-bit original, but then many people would not have been able to participate. One of
the 16-bit files could have served as the reference. Ethan assumed that the dithered
16-bit file should have been rated the best-sounding if it were distinguishable from the
truncated 16-bit file at all. But this is only an assumption! Perhaps the next best
reference file after the 24-bit original would have been a dithered 16-bit file with
noise-shaping designed to take advantage of the shape of the human ear's frequency (ATH)
curve. Naoki Shibata's free Sample Rate
Converter will perform this type of noise shaping.
Since the quality of each file was not rated, the
relative quality rankings of the files had to be inferred from the listener comments. The
statistical methods used to evaluate rankings are less powerful than the methods used to
evaluate listener ratings. There is another problem with using listener rankings: there is
a danger of the test goal becoming a contest to determine who can correctly identify the
most files correctly. Comments from people wishing to maximize their "score" are
likely to be very different from those of people honestly assessing sound quality.
2. The listening order of the files should have been
randomized. The effect of having a non-random listening order cannot be estimated, but a
random listening order would have removed any possible effects. There is a filename
randomizer on my site at: http://ff123.net/random/random.html.
In addition to the listening order, the actual naming of the files by Ethan should have
been randomized. Ethan ordered the file from best to worst (again assuming the dithered
16-bit file was best). Reading the listener comments, it is possible to argue that the one
person who correctly identified all 5 files really just surmised that Ethan had ordered
the files from best to worst instead of hearing the differences. It would have been
preferable if Ethan had removed all possibility of this occurring by naming the files
without any sort of pattern.
3. Ideally, every participant would have reported ABX results, comparing each file of interest to the
reference. However, considering that ABX takes some practice to become proficient in, and
that it takes a lot more effort and time to listen to files this way, perhaps that would
have been asking too much of the participants.
How Difficult Is It To Get A
"Perfect" Score By Guessing?
For this type of test, in which the object was to match
up the files to the correct bit depth, the probability of getting a perfect score if a
listener just guesses is (1/5) * (1/4) * (1/3) * (1/2) = 1/120. However, if one is able to
confidently identify the two worst files, then the probability of getting them all right
by guessing at the rest is only 1/6. Ironically, an extremely sensitive listener can have
a worse chance of getting a perfect score on this test than a less sensitive listener if
the more sensitive listener mistakenly identifies the "best" file as sounding
second best! See critique 1 above under the Test Method section.
Analysis of Group Results
The following scores were assigned for the listeners
listed on the Listener
Comments page. Listeners with blank scores either didn't rank the files or assigned
ambiguous rankings. Listener 11 submitted a ranking from another person in addition to his
own, so I listed these scores as 11a and 11b. If there is a tie in the file rankings, then
the average of the ranks are assigned to all the tied files. Listener 18 did not
distinguish any of the files from each other and can be eliminated as a useful data point.
File1 = 16-bit file, dithered
File2 = 16-bit file, truncated
File3 = 13-bit file
File4 = 11-bit file
File5 = 9-bit file
The data below is formatted for ready copy and paste
into my web statistical utility at http://ff123.net/friedman/stats.html. This performs a non-parametric
(based on rankings, not ratings) analysis of the data, using a non-parametric version of
Fisher's Least Significant Difference to separate the ranksums if the Friedman statistic
is determined to be significant. The reference for this type of analysis is Sensory
Evaluation Techniques, 3rd Ed. by Meilgaard, Civille, and Carr, 1999, CRC Press LLC,
pp. 289-292. For a more detailed example of this type of analysis, including formulas,
refer to my web page at http://ff123.net/dogies/dogies_plots.html.
The output of the utility is as follows. The
significant results are listed at the bottom of the output. This is saying that only File4
and File5 are distinguishable as being significantly worse than the others. Actually, more
precisely, File4 is identified as being significantly worse than only File2; however File5
is worse than every other file.
FRIEDMAN version 1.24 (Jan 17, 2002) http://ff123.net/
Friedman Analysis
Number of listeners: 21
Critical significance: 0.05
Significance of data: 3.23E-05 (highly significant)
Fisher's protected LSD for rank sums: 20.084
Ranksums:
File2
|
File1
|
File3
|
File4
|
File5
|
84.00
|
69.50
|
67.50
|
57.50
|
36.50
|
---------------------------- p-value Matrix ---------------------------
|
File1
|
File3
|
File4
|
File5
|
File2
|
0.157
|
0.107
|
0.010*
|
0.000*
|
File1
|
0.845
|
|
0.242
|
0.001*
|
File3
|
0.329
|
|
|
0.002*
|
File4
|
|
|
|
0.040*
|
-----------------------------------------------------------------------
File2 is better than File4, File5
File1 is better than File5
File3 is better than File5
File4 is better than File5
It is possible (though one has to be very careful) to
mine the data further. For example, if one chooses to eliminate all listeners who could
not identify file 5 and file 4 as sounding worst and second worst, respectively, then the
data becomes:
FRIEDMAN version 1.24 (Jan 17, 2002) http://ff123.net/
Friedman Analysis
Number of listeners: 10
Critical significance: 0.05
Significance of data: 3.75E-07 (highly significant)
Fisher's protected LSD for rank sums: 13.859
Ranksums:
File2
|
File3
|
File1
|
File4
|
File5
|
45.00
|
39.00
|
36.00
|
20.00
|
10.00
|
---------------------------- p-value Matrix ---------------------------
|
File3
|
File1
|
File4
|
File5
|
File2
|
0.396
|
0.203
|
0.000*
|
0.000*
|
File3
|
|
0.671
|
0.007*
|
0.000*
|
File1
|
|
|
0.024*
|
0.000*
|
File4
|
|
|
|
0.157
|
-----------------------------------------------------------------------
File2 is better than File4, File5
File3 is better than File4, File5
File1 is better than File4, File5
Now File 4 is definitely worse than the other files
(excepting File5), but interestingly, File4 is not significantly better than File5! Such
is the nature of the Fisher LSD.
Individual ABX Results
In contrast to the group results, two individuals
showed that they could distinguish between the two 16 bit files. These are Cameron Bobro's
comments:
I downloaded the bit-test files and took a listen. My
ratings:
File 2: best all around
File 3: sounds like number 2 but with the life sucked out
File 1: somehow odd
File 4: noisey
File 5: very noisey
So I guess it would be:
File 2: dithered
File 3: truncated
File 1: "13" bits
File 4: "11" bits
File 5: "9" bits
Of course it's hard to believe that anyone would go by
the numbers rather than just using whatever sounds best to them on their particular system
for a particular recording.
Here are Bobro's ABX results (19 correct
identifications out of 24 total trials; no "cherry-picking" to select the best
sessions or runs). My ABX
calculator says that the probability of getting these results by chance is a very slim
0.004.
The ABX program is great! Thanks. Well, I can hear
which one is which in the ABX, I'm really grateful you've removed any doubts I had that I
might be imagining these things. Because when my wife conducts blind tests on me it is
entirely possible that I know her well enough to second guess what "random
order" she's using.
Here's the BIG BUT: I've been firing up the ABX with
File 1 and 2 on and off since yesterday morning, just in between other things with long
breaks. A quick listen to first few seconds of each file, that one's that, no prob.
BUT those were spaced sets of 1, 2 and 3 trials over a
whole day. AND I wasn't really ABX'ing, I was listening for File 2, which has more pizazz
than File 1, and going from there. In other words saying which one was which and then
matching X to A or B. If this was with files I'd never heard and whose character I didn't
know beforehand, I guarantee that I would have done much worse.
I first tried a longer session, 13 in quick sucession
without pause (that's the "same" riff 39 times in a row, LOL). This kind of
trial is horrible. My ears crapped out after 5 trials. From number 6- couldn't hear one
damn bit of difference and just went on feeling, plain and simple.
Masochistic run of 8 out of 13 plus widely spaced runs
of 1, 2 and 3 adding up to 11 out of 11- altogether, 19 out of 24, .004.
The real-life answer AFAIC- I can hear the difference
with fresh ears but NOT with the slightest fatigue or loss of concentration. I would say
that many people may be deluding themselves into thinking they can't hear differences or
even more likely just don't have detailed enough monitoring systems. I'm listening over
Sennheiser HD-600's.
It bothers me a great deal to be scientifically shown
how quickly my perspective goes out of whack, so much for "crowing about
hearing".
Forgetting the numbers, what are the MUSICAL
conclusions? Well for one thing I'm very glad that I'll soon be getting some very nice and
non-fatiguing studio nearfields. Ethan really is a consumer advocate, with this test he's
placed the last stamp of approval on my decision to lay down some fairly serious cash.
Thanks again, ff123, for the ABX program. The
playback isn't as detailed as Samplitude's (in the ABX the telltale "waffle"
3/4's of the way through File 1 is not audible) but it's not a mastering program and
doesn't need to be. In another test with my own stuff, the ABX debunked an illusion I had
about two other files- those particular files are really either the same or "might as
well be", which is good to know. (*)
Bobro clarified further:
First I did 13 trials right off the bat in quick
succession. The first were clear, I thought it would be a cakewalk, but the last of those
13 I heard no difference at all, and just guessed. Then I realized what was going on and
did the 11 over the rest of the day (actually number 11 first thing this morning before
listening to anything else, that one jumped right out). A set of 3, then 2 sets of 2 then
four times just one listen. I knew that if I did sets of say 6, it would take a looong
time, if ever, to get the "stat" because after hearing a file more than a dozen
times in a row, it's a just a blur.
An unfamiliar full orchesration would be a better test
I think, especially as there are jangly metallic sounds in these examples, which betray
any monkey business in the upper frequencies. But even then there's the huge variable of
"which dither? What depth?". I'd be up for doing a test like that with the ABX,
though.
Anyway the biggest problem is trying to match up
everything you hear with knowledge and practice. Until recently, my mixes sounded, well,
like there's a thick blanket over them to be extremely polite.  Doesn't do any good at all to hear high frequencies if you
don't know that you have to mix in mono to get translatable mixes and no phasing problems,
LOL.
Doesn't do any good at all to hear high frequencies if you
don't know that you have to mix in mono to get translatable mixes and no phasing problems,
LOL.
To keep things in perspective- at this time I'm not
investing in better dither but in some seriously good monitors. IMO the value of these
kinds of tests isn't to prove some kind of universal truths, but to help find what's
important for the individual to improve their own sound.
Well I've changed my mind about Ethan's motivations. It
does take quite a circus to analize the subtilties, and even though they add up, the wise
consumer should invest first in more important things than better gadgets. He's obviously
invested in building a good room before an expensive soundcard, which is the musical
approach IMO.
And finally:
Hehe! I just couldn't listen all the way through the
files each time, it was tedious enough as it was. There's a "droop" in the timbre in the fadeout of File 1, too.
I don't know if Ethan still has my emails, but I wrote
to him after submitting my reaction to the test saying that we had been doing just such
blind tests. He said, great, but mentioned the danger of blind tests, which is imagining
differences that aren't there. That is true and got me to wondering if I had imagined
things and only been extremely lucky saying "that's File 1, that's 3" and so on
to my wife. So I inverted files and lined them up on the sample level.
I did this with 1,2 and 3, not bothering with 4 and 5
because they were too obvious.
As I wrote to Ethan, the "ghost" of the
difference was very obvious in the tails, but since that involves the variable of a
fadeout, I've pretty much ignored the fadeouts in these tests.
Only 1 and 2 came close to cancelling each other out,
but as I wrote to Ethan, you can hear a high fuzzy sound when listening to 1 and 2
"cancelling". He said, that's because one of them has dither. I then realized
that I'd ordered the files incorrectly in my guesses, but wasn't concerned because having
heard the differences I was prepared to learn how to equate them with the technical
differences.
Then Ethan implied on another forum that incorrectly
ordering the files according to their technical identity was the same as not hearing the
differences between them and that made me very angry.  This is the reason why the ABX test is so cool. There
isn't a second level of testing the correlation between what you hear and your technical
understanding of what it's called, it's a pure test of hearing differences.
This is the reason why the ABX test is so cool. There
isn't a second level of testing the correlation between what you hear and your technical
understanding of what it's called, it's a pure test of hearing differences.
Well in spite of all I've read I'm still not sure about
things like the difference between truncation and rounding. There was a good explaination
on another forum about dithering and I think I finally understand how dithering depths can
be fractions, and why you get that clearly audible itchy wooly blanket when you set very
deep dithering depths for example.
One other listener produced a significant ABX result
between file 1 and file 2. Here are his listening comments, which agree with Bobro's. ABX
of 7 out of 8 says that the probability is 0.035 that his results were by chance. This
listener said that file 2 was "sharper." Bobro had said that file 2 had more
"pizazz."
File 5 is worse (the noise can be heard all along, not
only at the end). I didn't take the time to listen to File 4, that was bad with headphones
This time, File 2 seems better (sharper) than file 1
ABX test (without DSP) : 7/8 (yesterday, with
headphones, File 2 seemed also better than file 3, but I got 5/8 only at ABX, so I didn't
report it, it was a vague feeling) Trying 16 ABX at lower volume (because of neighbours) :
10/16 only
File 2 seems also sharper than File 3
ABX : 10/16 only
Conclusion:
Best : File 2
then File 1 and 3
then file 4
Worst : File 5
(*) Arny Krueger, author
of PC-ABX, responds to the point concerning playback accuracy of his program:
I don't know what Samplitude does to .wav files, but I
know for sure that PCABX is absolutely bit-perfect. I tested this by playing 16 and 24 bit
files with PCABX.EXE through the digital output of one sound card and into the digital
input of another. BTW, I repeated this test in the analog domain to get an idea of how
long it takes to switch files with the switching delay set to zero.
PCABX.EXE is a Visual Basic program that never gets any
closer to the files than their names. It starts and stops the Windows multimedia .wav file
player on cue, running in millisecond increments.
Samplitude may do some resampling of .wav files when it
plays them, as I know for sure there are situations where CoolEdit Pro resamples to play
24 bit files on computers with 16 bit sound cards. It doesn't change the files unless you
formally ask it to, but it does do some processing that might be hidden to some when it
plays files. AFAIK it won't change sample rates except when formally asked to.
Return to
ff123's Home Page
Entire contents of this web site Copyright ©
1997- by Ethan Winer. All rights reserved.







